Rails
当然
检测性能问题
最好
在生产期间
其中
最后
接下来
N+1 查询问题
N+1 查询问题是 Rails 应用
清单 1. 未优化
<%@posts = Post.all(@posts).each do |p|%>
<h1><%=p.category.name%></h1>
<p><%=p.body%></p>
<%end%> 答案:上述代码生成了
立即加载 意味着 Rails 将自动执行所需
清单 2. 用立即加载优化后
<%@posts = Post.find(:all, : =>[:category]
=>[:category]
@posts.each do |p|%>
<h1><%=p.category.name%></h1>
<p><%=p.body%></p>
<%end%> 该代码最多生成两个查询
当然
测试 N+1
使用清单 3 内
清单 3. 立即加载基准测试脚本
require 'rubygems'
require 'faker'
require 'active_record'
require 'benchmark'
# This call creates a connection to our database.
ActiveRecord::Base.establish_connection(
:adapter => "mysql",
:host => "127.0.0.1",
:username => "root", # Note that while this is the default  ting for MySQL,
ting for MySQL,
:password => "", # a properly secured system will have a d ferent MySQL
ferent MySQL
# username and password, and so, you'll need to
# change these tings.
:database => "test")
# First, up our database...
 Category < ActiveRecord::Base
Category < ActiveRecord::Base
end
unless Category.table_exists?
ActiveRecord::Schema.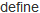 do
do
create_table :categories do |t|
t.column :name, :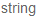
end
end
end
Category.create(:name=>'Sara Campbell\'s Stuff')
Category.create(:name=>'Jake Moran\'s Possessions')
Category.create(:name=>'Josh\'s Items')
number_of_categories = Category.count
Item < ActiveRecord::Base
belongs_to :category
end
# If the table doesn't exist, we'll create it.
unless Item.table_exists?
ActiveRecord::Schema. do
create_table :items do |t|
t.column :name, :
t.column :category_id, :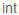 eger
eger
end
end
end
puts "Loading data..."
item_count = Item.count
item_table_size = 10000
item_count < item_table_size
(item_table_size - item_count).times do
Item.create!(:name=>Faker.name,
:category_id=>(1+rand(number_of_categories.to_i)))
end
end
puts "Running tests..."
Benchmark.bm do |x|
[100,1000,10000].each do |size|
x.report "size:#{size}, with n+1 problem" do
@items=Item.find(:all, :limit=>size)
@items.each do |i|
i.category
end
end
x.report "size:#{size}, with :" do
@items=Item.find(:all, :=>:category, :limit=>size)
@items.each do |i|
i.category
end
end
end
end 这个脚本使用 :
在我
清单 4. 立即加载
-- create_table(:categories)
-> 0.1327s
-- create_table(:items)
-> 0.1215s
Loading data...
Running tests...
user system total real
size:100, with n+1 problem 0.030000 0.000000 0.030000 ( 0.045996)
size:100, with : 0.010000 0.000000 0.010000 ( 0.009164)
size:1000, with n+1 problem 0.260000 0.040000 0.300000 ( 0.346721)
size:1000, with : 0.060000 0.010000 0.070000 ( 0.076739)
size:10000, with n+1 problem 3.110000 0.380000 3.490000 ( 3.935518)
size:10000, with : 0.470000 0.080000 0.550000 ( 0.573861) 在所有情况下
嵌套
如果您想要引用
清单 5. 嵌套
@posts = Post.all
@posts.each do |p|
<h1><%=p.category.name%></h1>
<%=image_tag p.author.image.public_filename %>
<p><%=p.body%>
<%end%> 此代码和的前
正确
清单 6. 嵌套
@posts = Post.find(:all, :=>{ :category=> ,
,
:author=>{ :image=>}} )
@posts.each do |p|
<h1><%=p.category.name%></h1>
<%=image_tag p.author.image.public_filename %>
<p><%=p.body%>
<%end%> 正如您所见
间接
并非所有
清单 7. 间接
<%@user = User.find(5)
@user.posts.each do |p|%>
<%=render :partial=>'posts/summary', :locals=>:post=>p
%> <%end%> 当然
清单 8. 间接立即加载 partial: posts/_summary.html.erb
<h1><%=post.user.name%></h1> 不幸
修复思路方法是使用自引用
清单 9. 间接
<%@user = User.find(5, :=>{:posts=>[:user]})
...snip... 虽然有悖于直觉
当然
Rails 分组和聚合计算
您可能遇到
清单 10. 执行分组计算
all_ages = Person.find(:all).group_by(&:age).keys.uniq
oldest_age = Person.find(:all).max 相反
清单 11. 执行分组计算
all_ages = Person.find(:all, :group=>[:age])
oldest_age = Person.calcuate(:max, :age) ActiveRecord::Base#find 有大量选项可用于模仿 SQL
不过
用 Rails 定制 SQL
假设有这样
清单 12. 用 ActiveRecord 定制 SQL
sql = "SELECT profession,
AVG(age) as average_age,
AVG(accident_count)
FROM persons
GROUP
BY profession"
Person.find_by_sql(sql).each do |row|
puts "#{row.profession}, " <<
"avg. age: #{row.average_age}, " <<
"avg. accidents: #{row.average_accident_count}"
end 这个脚本应该能生成清单 13 所示
清单 13. 用 ActiveRecord 定制 SQL
Programmer, avg. age: 18.010, avg. accidents: 9
 Administrator, avg. age: 22.720, avg. accidents: 8
Administrator, avg. age: 22.720, avg. accidents: 8 当然
清单 14. 用 ActiveRecord 定制非查找型 SQL
ActiveRecord::Base.connection.execute "ALTER TABLE some_table CHANGE COLUMN..." 大多数
结束语
和所有

最新评论