rubyonrails:ruby 标准类型整理总结
 、数字
、数字
- Ruby支持整数和浮点数
 整数可以是任意长度
整数可以是任意长度
- 定范围内
 整数以 2进制存放它们属于fixnum类型当超出这个范围时则自动转换为bignum类型
整数以 2进制存放它们属于fixnum类型当超出这个范围时则自动转换为bignum类型
- 表达方式:符号+串
 数字串中下划线会被忽略(前缀包括:0表示 8进制, 0x表示十 6进制, 0b表示 2进制)123_456_789_123_345_789 # Bignum
数字串中下划线会被忽略(前缀包括:0表示 8进制, 0x表示十 6进制, 0b表示 2进制)123_456_789_123_345_789 # Bignum
0xaabb # 十 6进制
- 也可以通过在前面加上问号来得到ASCII码对应整数值和转义序列值
?a # 普通
?\n # 换行符 (0x0a)
?\C-a # CTRL+a (0x01)
?\M-a # ALT+a
?\M-\C-a # CTRL+ALT+a
?\C-? # 删除键
- 个带小数点数字字面值被转换成Float对象
- 所有数字都是对象,不存在相应
 而是思路方法
而是思路方法
exp:
数字绝对值是aNumber.abs而不是abs(aNumber)
- 整数有用迭代器
3.times { pr "X " } => X X X 1.upto(5) { |i| pr i, " " } =>1 2 3 4 5 99.downto(95) { |i| pr i, " " }=>99 98 97 96 95 50.step(80, 5) { |i| pr i, " " }=>50 55 60 65 70 75 80
2、串
"X " } => X X X 1.upto(5) { |i| pr i, " " } =>1 2 3 4 5 99.downto(95) { |i| pr i, " " }=>99 98 97 96 95 50.step(80, 5) { |i| pr i, " " }=>50 55 60 65 70 75 80
2、串
- Ruby串是8位字节简单序列串是String类对象
- 注意转换机制(注意单引号和双引号区别)如:
单引号中两个相连反斜线被替换成个反斜线个反斜线后跟个单引号被替换成个单引号
'escape using "\\"' >> 转义为"\" 'That\'s right' >> That's right
- 双引号支持多义转义
"\n"#{expr}序列来替代任何Ruby表达式值 ,(全局变量、类变量或者例子变量那么可以省略大括号)"Seconds/day: #{24*60*60}" >> Seconds/day: 86400 "#{'Ho! '*3}Merry Christmas" >> Ho! Ho! Ho! Merry Christmas "This is line #$." >> This is line 3
- here document来创建个串,end_of_
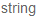 为结束符号
为结束符号
aString = <<END_OF_STRING The body of the is the input lines up to one ending with the same text that followed the '<<' END_OF_STRING
- %q和%Q分别把串分隔成单引号和双引号串(即%q和%Q后面符号具有',"功能)
%q/general single-quoted / >> general single-quoted
- String 常用功能
String#split:把行分解成字段
String#chomp:去掉换行符
String#squeeze:剪除被重复输入
String#scan:以指定想让块匹配模式
exp:/jazz/j00132.mp3 | 3:45 | Fats Waller | Ain't Misbehavin'
/jazz/j00319.mp3 | 2:58 | Louis Armstrong | Wonderful World
#文件格式如上要进行分解songs = SongList.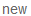
songFile.each do |line|
file, length, name, title = line.chomp.split(/\s*\|\s*/)#先chomp,后再分解/\s*表示任
name.squeeze!(" ")#替换空格
mins, secs = length.scan(/\d+/)#这里用scan匹配模式
songs.append Song.(title, name, mins.to_i*60+secs.to_i)
end
3、区间
- 区间存在于任何地方如:1到12月
 ruby用区间实现了3个区别特性:序列条件间隔
ruby用区间实现了3个区别特性:序列条件间隔
- "..":两个点号创建个闭区间"...":而 3个点号创建个右开区间(即右边界不取值)
exp:0..anArray.length-1 等同于 0...anArray.length
- to_a 把区间转换成列表
exp: ('bar'..'bat').to_a >> ["bar", "bas", "bat"]
- 区间共它使用方法
digits = 0..9
digits. ?(5) >> true
?(5) >> true
digits.min >> 0
digits.max >> 9
digits.reject {|i| i < 5 } >> [5, 6, 7, 8, 9]
digits.each do |digit|
dial(digit)
end
- ruby能把基于自己定义对象区间要求:这个对象必须能够响应succ思路方法来返回序列中下个对象并且这个对象必须能够使用<=>运算符来被比较即常规比较运算符
- 间隔测试
puts (1..10).?(3.14)=> ture
puts (1..10)  = 3.14 => ture
= 3.14 => ture
4、正则表达式
- 正则表达式是Regexp类型对象可以使用构造器显式地创建个正则表达式也可以使用字面值形式/pattern/和%r\pattern\来创建
- 用Regxp#match(aString)形式或者匹配运算符=~(正匹配)和!~(负匹配)来匹配串了匹配运算符在String和Regexp中都有定义如果两个操作数都是串则右边那个要被转换成正则表达式
exp:
a = "Fats Waller"
a =~ /a/ >> 1
a =~ /z/ >> nil
a =~ "ll" >> 7
- 上面返回是匹配位置其它
$&接受被模式匹配到串部分
$`接受匹配的前串部分
$'接受的后串
exp:下面思路方法后继都会用到
def showRE(a,re)
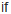 a =~ re
a =~ re
"#{$`}<<#{$&}>>#{$'}" #返回前、中、后

"no match"
end
end
- 模式任何个表达式都包含个模式它用来把正则表达式和字任串匹配
模式中除了., |, (, ), [, {, +, \, ^, $, *,和?以外字任都匹配它自己
如果要匹配这些特殊就需要加上反斜线做前缀分析上面例字
/\s*\|\s*/,在\s和|的前都加了/做前缀showRE('kangaroo', /angar/) >> k<<angar>>oo
showRE('!@%&-_=+', /%&/) >> !@<<%&>>-_=+
showRE('yes | no', /\|/) >> yes <<|>> no
- \后跟个字母或数字表示个特定结构如\s表示等
- 锚点 个正则表达式总是返回找到模式第个匹配如何改变?
模式^和$分别用来匹配行首和行尾
序列\A匹配串开始位置\z和\Z匹配串结尾位置
\b和\B分别匹配字边界和非字边界
showRE("this is\nthe time", /^the/) >> this is\n<<the>> time
showRE("this is\nthe time", /is$/) >> this <<is>>\nthe time
showRE("this is\nthe time", /\Athis/) >> <<this>> is\nthe time
5、类
- 这里类不是面向对象类只表示这些这属于个特殊种类
- 类是用方括号扩起来集合:[characters]匹配方括号中所有单[aeiou]匹配元音[,.:'!?]匹配标点符号等等
showRE('It costs $12.', /[aeiou]/) >> It c<<o>>sts $12.
- 在方括号中序列c1-c2表示在c1-c2的间也包括c1和c2所有
a = 'Gamma [Design Patterns-page 123]'
showRE(a, / ]/) >> Gamma [Design Patterns-page 123<<]>>
]/) >> Gamma [Design Patterns-page 123<<]>>
showRE(a, /[B-F]/) >> Gamma [<<D>>esign Patterns-page 123]
showRE(a, /[-]/) >> Gamma [Design Patterns<<->>page 123]
showRE(a, /[0-9]/) >> Gamma [Design Patterns-page <<1>>23]
- 紧跟在开括号([)后是^这表示这个类否定:[^a-z]匹配任何不是小写字母
- 类缩写
序列 形如 [ ... ] 含义
\d [0-9] Digit character
\D [^0-9] Nondigit
\s [\s\t\r\n\f] Whitespace character 匹配个单空白符
\S [^\s\t\r\n\f] Nonwhitespace character
\w [A-Za-z0-9_] Word character
\W [^A-Za-z0-9_] Nonword character
- 重复
r * 匹配0个或多个r出现
r + 匹配个或多个r出现
r ? 匹配0个或1个r出现
r {m,n} 匹配最少m最多n个r出现
r {m,} 匹配最少m个r出现
重复结构有高优先权:即它们仅和模式中直接正则表达式前驱捆绑
/ab+/匹配个"a"后跟个活着多个"b"而不是"ab"序列
/a*/会匹配任何串:0个或者多个"a"任意串
exp:
a = "The moon is made of cheese"
showRE(a, /\w+/) >> <<The>> moon is made of cheese
showRE(a, /\s.*\s/) >> The<< moon is made of >>cheese
showRE(a, /\s.*?\s/) >> The<< moon >>is made of cheese
showRE(a, /[aeiou]{2,99}/) >> The m<<oo>>n is made of cheese
showRE(a, /mo?o/) >> The <<moo>>n is made of cheese
- 替换
"|"既匹配它前面正则表达式或者匹配后面a = "red ball blue sky"
showRE(a, /d|e/) >> r<<e>>d ball blue sky
showRE(a, /al|lu/) >> red b<<al>>l blue sky
showRE(a, /red ball|angry sky/) >> <<red ball>> blue sky
- 分组
圆括号把正则表达式分组组中内容被当作个单独正则表达式
showRE('banana', /(an)+/) >> b<<anan>>a
# 匹配重复字母
showRE('He said "Hello"', /(\w)\1/) >> He said "He<<ll>>o"
# 匹配重复子串
showRE('Mississippi', /(\w+)\1/) >> M<<ississ>>ippi
- 基于模式替换你是否想过大小写替换
思路方法String#sub和String#gsub都在串中搜索匹配第个参数部分然后用第 2个参数来替换它们String#sub只替换次而String#gsub替换所有找到匹配都返回个包含了替换新串拷贝进化版本是String#sub!和 String#gsub!a = "the quick brown fox"
a.sub(/[aeiou]/, '*') >> "th* quick brown fox"
a.gsub(/[aeiou]/, '*') >> "th* q**ck br*wn f*x"
a.sub(/\s\S+/, '') >> "the brown fox"
a.gsub(/\s\S+/, '') >> "the"
第 2个参数可以是代码块a = "the quick brown fox"
a.sub (/^./) { $&.up } >> "The quick brown fox"
} >> "The quick brown fox"
a.gsub(/[aeiou]/) { $&.up } >> "thE qUIck brOwn fOx"
- 反斜线序列用在替换中\& 后面匹配
\+ 后面匹配组
\` 匹配前面串
\' 匹配后面串
\\ 反斜线字面值
- 面向对象正则表达式
正则表达式字面值创建Regexp类
re = /cat/
re.type >> Regexp思路方法Regexp#match从串中匹配个正则表达式如果不成功思路方法返回nil如果成功返回MatchData类个例子
exp:e = /(\d+):(\d+)/ # match a time hh:mm
md = re.match("Time: 12:34am")
md.type >> MatchData
md[0] # $& >> "12:34"
md[1] # $1 >> "12"
md[2] # $2 >> "34"
md.pre_match # $` >> "Time: "
md.post_match # $' >> "am"
延伸阅读

最新评论