1、硬件、软件准备
手头上有三台配置一样的电脑,就不去装虚拟机了,配置如下:CPU:Intel(R) Pentium(R) Dual CPU E2200 @ 2.20GHz
Memory:2001MiB
Network:NetLink BCM5786 Gigabit Ethernet
三台电脑装有相同的操作系统——Ubuntu 11.04
2、安装过程
任选一台机器作为master,其他机器作为slaves,所有机器拥有相同的用户、相同的环境变量配置、相同的hadoop目录结构、相同的Java目录结构。(1)、更改host文件
master机器:在终端执行:sudo gedit /etc/hosts,添加以下信息:172.22.9.209 namenode-m
172.22.9.185 datanode-1
172.22.9.220 datanode-2
slaves机器:处理方式类似。
(2)、安装SSH
1)、为所有机器安装ssh:在终端运行:sudo apt-get install ssh,查看/leozhang目录下是否有.ssh文件夹(需要View->Show Hidden Files才能看见隐藏文件),如果没有,在终端运行:sudo mkdir .ssh;2)、在终端运行:
cd .ssh
#生成公钥、私钥密钥对
ssh-keygen #一直回车
#将公钥内容复制到authorized_keys文件 cp id_rsa.pub authorized_keys
#设定authorized_keys文件属性为-rw-r--r--,即文件属主拥有读写权限,与文件属主同组的用户拥有读权限,其他人拥有读权限。
chmod 644 authorized_keys
#将公钥拷贝到slaves
scp authorized_keys datanode-1:/home/leozhang/.ssh #这里也可以是scp authorized_keys leozhang@datanode-1:/home/leozhang/.ssh
scp authorized_keys datanode-2:/home/leozhang/.ssh #同上
最后测试设置是否成功,如:ssh datanode-1,如果不用输入密码就能登录,说明设置成功。
(3)、下载并配置jdk
1)、从http://www.oracle.com/technetwork/java/javase/downloads/java-se-jdk-7-download-432154.html下载jdk-7-linux-i586.tar.gz,解压后得到文件夹:jdk1.7.0,(例如下载并解压到了:/home/leozhang/Downloads);2)、在所有机器上做如下操作:在/usr建立文件夹java:在终端执行:sudo mkdir /usr/java,并将jdk1.7.0拷贝到java文件夹:进入/home/leozhang/Downloads目录,在终端执行sudo mv jdk1.7.0 /usr/java;
3)、在终端执行:sudo gedit /etc/profile,在文件末尾添加:
JAVA_HOME="/usr/java/jdk1.7.0"
export JAVA_HOME
PATH=$JAVA_HOME/bin:$PATH
export PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASSPATH
export CLASSPATH
4)、在终端执行:
cd /usr/java
scp -r java1.7.0 leozhang@datanode-1:/usr/java
scp -r java1.7.0 leozhang@datanode-2:/usr/java
(4)、下载并配置hadoop
hadoop包含三个部分:Hadoop Common: The common utilities that support the other Hadoop subprojects.
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
Hadoop MapReduce: A software framework for distributed processing of large data sets _disibledevent=>http://labs.renren.com/apache-mirror//hadoop/core/hadoop-0.20.204.0/下载hadoop-0.20.204.0.tar.gz,解压到home/leozhang中并重命名为hadoop;
2)、在终端执行:sudo gedit /etc/profile,在文件末尾添加:
HADOOP_HOME=/home/leozhang/hadoop
export HADOOP_HOME
export HADOOP=$HADOOP_HOME/bin
export PATH=$HADOOP:$PATH
3)、hadoop配置文件
在hadoop文件夹中有一个conf文件夹,里面是hadoop所需的配置文件,主要关注的有以下几个:
●hadoop-env.sh
需要改动的只有一处,设置JAVA_HOME。
# The java implementation to use. Required. export JAVA_HOME=/usr/java/jdk1.7.0
●core-site.xml
fs.default.name指出NameNode所在的地址,NameNode要跑在master机器上。
●hdfs-site.xml
dfs.replication默认是3,如果DataNode个数小于3会报错。
●mapred-site.xml
mapred.job.tracker指出jobtracker所在地址,其它项不去配置则都为默认值。
关于配置文件的详细信息可以在http://hadoop.apache.org/common/docs/stable/cluster_setup.html中找到。
●masters
172.22.9.209
●slaves
172.22.9.185 172.22.9.220
4)、在终端执行:
cd /home/leozhang
scp -r hadoop leozhang@datanode-1:/home/leozhang
scp -r hadoop leozhang@datanode-2:/home/leozhang
5)、在终端执行:source /etc/profile,如果不管用就注销然后重新登录。
3、数据全局排序
(1)、工具准备
需要下载eclipse,地址是http://www.eclipse.org/downloads/,也可以在终端运行sudo apt-get install eclipse,可以装个mapreduce的插件,方便在单机调试代码,那个插件在下载的hadoop的目录里,如:/home/leozhang/hadoop/contrib/eclipse-plugin/hadoop-eclipse-plugin-0.20.204.0.jar,把它拷贝到eclipse安装目录的plugins文件夹中即可。(2)、启动hadoop
第一次使用需要初始化NameNode,在master机器的终端上执行:hadoop namenode -format;在master机器的终端上执行:start-all.sh,可以用jps来查看本机的java进程,在master上启动了3个进程:JobTracker、SecondaryNameNode、NameNode,而slaves机器上有2个进程:TaskTracker、DataNode;需要停止进程,只要在master机器的终端上执行:stop-all.sh。
在http://localhost:50070/可以看到NameNode的详细信息,如:
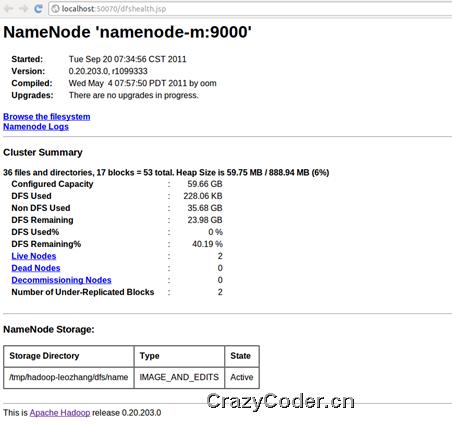 在http://localhost:50030可以看到作业的详细信息,如:
在http://localhost:50030可以看到作业的详细信息,如: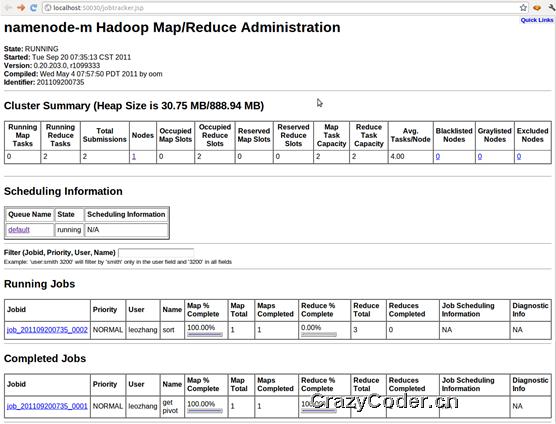
(3)、关于mapreduce
mapreduce很适合数据之间相关性较低且数据量庞大的情况,map操作将原始数据经过特定操作打散后输出,作为中间结果,hadoop通过shuffle操作对中间结果排序,之后,reduce操作接收中间结果并进行汇总操作,最后将结果输出到文件中,从这里也可以看到在hadoop中,hdfs是mapreduce的基石。可以用下面这幅图描述map和reduce的过程: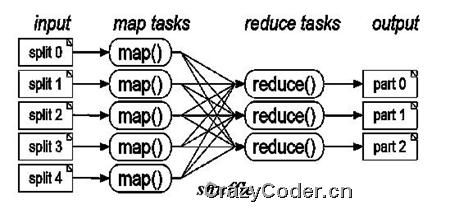
有人用这么一句话解释mapreduce:
We want to count all the books in the library. You count up shelf #1, I count up shelf #2. That's map. The more people we get, the faster it goes. 我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
Now we get together and add our individual counts. That's reduce. 现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
(4)、数据准备
将待排序文本上传到hdfs上并放在input文件夹中,在终端执行:hadoop dfs –mkdir input;假设数据文件data.txt放在本地磁盘的/home/leozhang/testdata中,在终端执行:cd /home/leozhang/testdata;hadoop dfs –put data input/
(5)、排序思路
借鉴快速排序的思路:假设为升序排序,那么每完成一次partition,pivot左边所有元素的值都小于等于pivot,而pivot右边的所有元素的值都大于等于pivot,如果现在有N个pivot,那么数据就被map成了N+1个区间,让reducer个数等于N+1,将不同区间的数据发送到相应区间的reducer;hadoop利用shuffle操作将这N+1份数据自动排序,reduce操作只需要接收中间结果后直接输出到文件即可。由此归纳出用hadoop对大量数据排序的步骤:
1)、对待排序数据进行抽样;
2)、对抽样数据进行排序,产生pivot(例如得到的pivot为:3,9,11);
3)、Map对输入的每条数据计算其处于哪两个pivot之间,之后将数据发给相应的reduce(例如区间划分为:<3、[3,9)、>=9,分别对应reducer0、reducer1、reducer2);
4)、Reduce将获得数据直接输出。
(6)、简单实现
数据抽样由:RandomSelectMapper和RandomSelectReducer完成,数据划分由ReducerPatition完成,排序输出由SortMapper和SortReducer完成,执行顺序为:RandomSelectMapper –> RandomSelectReducer –> SortMapper –> SortReducer。这个实现方式总觉得不给力,尤其是数据划分那块儿,不知道大家会怎么做,指导一下我吧,呵呵。代码可以从这里得到。
1)、pivot的选取采用随机的方式:
1: package MRTEST.Sort;
2:
3: import java.io.IOException;
4: import java.util.Random;
5: import java.util.StringTokenizer;
6:
7: import org.apache.hadoop.io.Text;
8: import org.apache.hadoop.mapreduce.Mapper;
9:
10: public class RandomSelectMapper
11: extends Mapper
12: private static int currentSize = 0;
13: private Random random = new Random();
14:
15: public void map(Object key, Text value, Context context)
16: throws IOException, InterruptedException{
17: StringTokenizer itr = new StringTokenizer(value.toString());
18: while(itr.hasMoreTokens()){
19: currentSize++;
20: Random ran = new Random();
21: if(random.nextInt(currentSize) == ran.nextInt(1)){
22: Text v = new Text(itr.nextToken());
23: context.write(v, v);
24: }
25: else{
26: itr.nextToken();
27: }
28: }
29: }
30:
31: }
pivot的排序由hadoop完成:
1: package MRTEST.Sort;
2:
3: import java.io.IOException;
4:
5: import org.apache.hadoop.io.Text;
6: import org.apache.hadoop.mapreduce.Reducer;
7:
8: public class RandomSelectReducer
9: extends Reducer
10:
11: public void reduce(Text key, Iterable
12: throws IOException, InterruptedException{
13:
14: for (Text data : values) {
15: context.write(null,data);
16: break;
17: }
18: }
19: }
2)、SortMapper直接读取数据:
1: package MRTEST.Sort;
2:
3: import java.io.IOException;
4: import java.util.StringTokenizer;
5:
6: import org.apache.hadoop.io.Text;
7: import org.apache.hadoop.mapreduce.Mapper;
8:
9: public class SortMapper
10: extends Mapper
11:
12: public void map(Object key, Text values,
13: Context context) throws IOException,InterruptedException {
14: StringTokenizer itr = new StringTokenizer(values.toString());
15: while (itr.hasMoreTokens()) {
16: Text v = new Text(itr.nextToken());
17: context.write(v, v);
18: }
19: }
20:
21: }
向相应的Reducer分发数据:
1: package MRTEST.Sort;
2:
3: import org.apache.hadoop.io.Text;
4: import org.apache.hadoop.mapreduce.Partitioner;
5:
6: public class ReducerPartition
7: extends Partitioner
8:
9: public int getPartition(Text key, Text value ,int numPartitions){
10: return HadoopUtil.getReducerId(value, numPartitions);
11: }
12: }
最后由SortReducer输出结果:
1: package MRTEST.Sort;
2:
3: import java.io.IOException;
4:
5:
6: import org.apache.hadoop.io.Text;
7: import org.apache.hadoop.mapreduce.Reducer;
8:
9: public class SortReducer
10: extends Reducer
11:
12: public void reduce(Text key, Iterable
13: Context context) throws IOException, InterruptedException {
14:
15: for (Text data : values) {
16: context.write(key,data);
17: }
18: }
19: }
3)、作业的组织由SortDriver完成:
1: package MRTEST.Sort;
2:
3: import java.io.IOException;
4:
5: import org.apache.hadoop.conf.Configuration;
6: import org.apache.hadoop.fs.Path;
7: import org.apache.hadoop.io.Text;
8: import org.apache.hadoop.mapreduce.Job;
9: import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
10: import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
11: import org.apache.hadoop.util.GenericOptionsParser;
12:
13:
14: public class SortDriver {
15:
16: public static void runPivotSelect(Configuration conf,
17: Path input,
18: Path output) throws IOException, ClassNotFoundException, InterruptedException{
19:
20: Job job = new Job(conf, "get pivot");
21: job.setJarByClass(SortDriver.class);
22: job.setMapperClass(RandomSelectMapper.class);
23: job.setReducerClass(RandomSelectReducer.class);
24: job.setOutputKeyClass(Text.class);
25: job.setOutputValueClass(Text.class);
26: FileInputFormat.addInputPath(job, input);
27: FileOutputFormat.setOutputPath(job, output);
28: if(!job.waitForCompletion(true)){
29: System.exit(2);
30: }
31: }
32:
33: public static void runSort(Configuration conf,
34: Path input,
35: Path partition,
36: Path output) throws IOException, ClassNotFoundException, InterruptedException{
37: Job job = new Job(conf, "sort");
38: job.setJarByClass(SortDriver.class);
39: job.setMapperClass(SortMapper.class);
40: job.setCombinerClass(SortReducer.class);
41: job.setPartitionerClass(ReducerPartition.class);
42: job.setReducerClass(SortReducer.class);
43: job.setOutputKeyClass(Text.class);
44: job.setOutputValueClass(Text.class);
45: HadoopUtil.readPartition(conf, new Path(partition.toString() + "\\part-r-00000"));
46: job.setNumReduceTasks(HadoopUtil.pivots.size());
47: FileInputFormat.addInputPath(job, input);
48: FileOutputFormat.setOutputPath(job, output);
49:
50: System.exit(job.waitForCompletion(true) ? 0 : 1);
51: }
52:
53: public static void main(String[] args) throws Exception {
54: Configuration conf = new Configuration();
55: String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
56: if (otherArgs.length != 3) {
57: System.err.println("Usage: sort

最新评论