1.
个非常简单

情形
输出档案(archive)类似于输出数据流(stream)

数据能通过<< 或 & 操作符存储到档案(archive)中:
ar << data;
ar & data;
输入档案(archive)类似于输入数据流(stream)
数据能通过>> 或 & 操作符从档案(archive)中装载
ar >> data;
ar & data;
对于原始数据类型
当这些操作

时候
数据是简单
“被存储/被装载” “到/从” 档案(archive)
对于类(
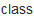
)数据类型
类
serialize

被
对上面
操作
每个serialize
用来“存储/装载”其数据成员
这个处理采用递归
方式
直到所有包含在类中
数据“被存储/被装载”
个非常简单
情形
通常用serialize
来存储和装载类
数据成员
这个库包含
个叫 demo.cpp

用于介绍如何用这个库
下面
我们从这个demo摘录代码
来介绍这个库应用
最简单情形
#
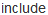
<fstream>
//
headers that implement a archive in simple text format
#
<boost/archive/text_oarchive.hpp>
#
<boost/archive/text_iarchive.hpp>
/////////////////////////////////////////////////////////////
// gps coordinate
//
// illustrates serialization for a simple type
//
gps_position
{
private:
friend
boost::serialization::access;
// When the
Archive corresponds to an output archive, the
// & operator is
d similar to <<. Likewise, when the
Archive
// is a type of input archive the & operator is
d similar to >>.
// 这个模板
序列化时被boost库
template<
Archive>
void serialize(Archive & ar, const unsigned

version)
{
ar & degrees;
ar & minutes;
ar & seconds;
}
degrees;
minutes;
float seconds;
public:
gps_position
{};
gps_position(
d,
m, float s) :
degrees(d), minutes(m), seconds(s)
{}
};

{
// create and open a character archive for output
std::ofstream ofs("filename");
boost::archive::text_oarchive oa(ofs);
// create
instance
const gps_position g(35, 59, 24.567f);
// write
instance to archive
oa << g;
// close archive
ofs.close
;
// ... some time later restore the
instance to its orginal state
// create and open an archive for input
std::
stream
s("filename", std::ios::binary);
boost::archive::text_iarchive ia(
s);
// read
state from archive
gps_position
g;
ia >>
g;
// close archive
s.close
;
0;
}
对于每个通过序列化“被存储”
类
必须存在
个
去实现“存储”其所有状态数据
对于每个通过序列化“被装载”
类
必须存在
个
来实现“装载”其所有状态数据
在上面
例子中
这些
是模板成员
serialize
2. 非侵入
版本
在上例是侵入
设计
类是需要由其例子来序列化
来改变
这在某些情形是困难
个等价
可选
设计如下:
#
<boost/archive/text_oarchive.hpp>
#
<boost/archive/text_iarchive.hpp>
gps_position
{
public:
degrees;
minutes;
float seconds;
gps_position
{};
gps_position(
d,
m, float s) :
degrees(d), minutes(m), seconds(s)
{}
};
// 注意命名空间
boost {
serialization {
template<
Archive>
void serialize(Archive & ar, gps_position & g, const unsigned
version)
{
ar & g.degrees;
ar & g.minutes;
ar & g.seconds;
}
} //
serialization
} //
boost
这种情况生成
serialize
不是gps_position类
成员
这有异曲同工的妙
非侵入序列化主要应用在不改变类定义就可实现类
序列化
为实现这种可能
类必须提供足够
信息来更新类状态
在这个例子中
我们假设类有public成员
仅当提供足够信息来存储和装载
类
才能不改变类自身
在外部来序列化类状态
3. 可序列化
成员
个可序列化
类
可拥有可序列化
成员
例如:
bus_stop
{
friend
boost::serialization::access;
template<
Archive>
void serialize(Archive & ar, const unsigned
version)
{
ar & latitude;
ar & longitude;
}
gps_position latitude;
gps_position longitude;
protected:
bus_stop(const gps_position & lat_, const gps_position & long_) :
latitude(lat_), longitude(long_)
{}
public:
bus_stop
{}
// See item # 14 in Effective C
by Scott Meyers.
// re non-virtual destructors in base
es.
virtual ~bus_stop
{}
};
这里
类类型
成员被序列化
恰如原始类型被序列化
样
注意
类bus_stop
例子“存储”时
其归档(archive)操作符将
latitude 和 longitude
serialize
这将依次
定义在gps_position中
serialize 来被“存储”
这种手法中
通过bus_stop
归档(archive)操作符,整个数据结构被存储,bus_stop是它
根条目
4. 派生类
派生类应包含其基类
序列化
#
<boost/serialization/base_object.hpp>
bus_stop_corner : public bus_stop
{
friend
boost::serialization::access;
template<
Archive>
void serialize(Archive & ar, const unsigned
version)
{
// serialize base
information
// 基类
序列化
ar & boost::serialization::base_object<bus_stop>(*this);
ar & street1;
ar & street2;
}
std::

street1;
std::
street2;
virtual std::
description
const
{
street1 + " and " + street2;
}
public:
bus_stop_corner
{}
bus_stop_corner(const gps_position & lat_, const gps_position & long_,
const std::
& s1_, const std::
& s2_
) :
bus_stop(lat_, long_), street1(s1_), street2(s2_)
{}
};
注意在派生类中不要直接
其基类
序列化
这样做看似工作
实际上绕过跟踪例子用于存储来消除冗余
代码
它也绕过写到档案中类
版本信息
代码
因此
总是声明serialize 作为私有
声明friend boost::serialization::access 将运行序列化库存取私有变量和
5. 指针
假设我们定义了bus route包含
组bus stops
假定:
我们可以有几种bus stop
类型(记住bus_stop是
个基类)
个所给
bus_stop可以展现多于
个
路线
个bus route 用
组指向bus_stop
指针来描述是方便
bus_route
{
friend
boost::serialization::access;
bus_stop * stops[10];
template<
Archive>
void serialize(Archive & ar, const unsigned
version)
{
i;
for(i = 0; i < 10;
i)
ar & stops[i];
}
public:
bus_route
{}
};
stops
每个成员将被序列化
但是
记住每个成员是个指针
- 实际含义是什么? 序列化整个对象是要求在另
个地方和时间重新构造原始数据结构
用指针为了完成这些
存储指针
值是不够
指针指向
对象必须存储
当成员最后被装载
个新
对象被创建
新
指针被装载到类
成员中
所有这
切是由序列化库自动完成
通过指针关联
对象
上述代码能完成存储和装载
6.
事实上上述方案比较复杂
序列化库能检测出被序列化
对象是
个
将产生上述等价
代码
因此上述代码能更短
写为:
bus_route
{
friend
boost::serialization::access;
bus_stop * stops[10];
template<
Archive>
void serialize(Archive & ar, const unsigned
version)
{
ar & stops;
}
public:
bus_route
{}
};
7. STL容器
上面
例子用
成员
更多
如此
个应用用STL容器为如此
目
序列化库包含为所有STL容器序列化
代码
因此
下种方案正如我们所预期
样子工作
#
<boost/serialization/list.hpp>
bus_route
{
friend
boost::serialization::access;
std::list<bus_stop *> stops;
template<
Archive>
void serialize(Archive & ar, const unsigned
version)
{
ar & stops;
}
public:
bus_route
{}
};
8. 类
版本
假设我们对bus_route类满意
在产品中使用它
段时间后
发觉bus_route 类需要包含线路驾驶员
名字
因此新版本如下:
#
<boost/serialization/list.hpp>
#
<boost/serialization/
.hpp>
bus_route
{
friend
boost::serialization::access;
std::list<bus_stop *> stops;
std::
driver_name;
template<
Archive>
void serialize(Archive & ar, const unsigned
version)
{
ar & driver_name;
ar & stops;
}
public:
bus_route
{}
};
好
完毕!异常...会发生在读取旧版本所生成
数据文件时
如何考虑版本问题?
通常
序列化库为每个被序列化
类在档案中存储版本号
缺省值是0
当档案装载时
存储
版本号可被读出
上述代码可修改如下:
#
<boost/serialization/list.hpp>
#
<boost/serialization/
.hpp>
#
<boost/serialization/version.hpp>
bus_route
{
friend
boost::serialization::access;
std::list<bus_stop *> stops;
std::
driver_name;
template<
Archive>
void serialize(Archive & ar, const unsigned
version)
{
// only save/load driver_name for
er archives
(version > 0)
ar & driver_name;
ar & stops;
}
public:
bus_route
{}
};
BOOST_CLASS_VERSION(bus_route, 1)
对每个类通过应用
版本
没有必要维护
个版本文件
个文件版本是所有它组成
类
版本
联合
系统允许
和以前版本
创建
档案向下兼容
9. 把serialize拆分成save/load
serialize
是简单
简洁
并且保证类成员按同样
顺序(序列化系统
key)被存储/被装载
可是有像这里例子
样
装载和存储不
致
情形
例如
个类有多个版本
情况发生
上述情形能重写为:
#
<boost/serialization/list.hpp>
#
<boost/serialization/
.hpp>
#
<boost/serialization/version.hpp>
#
<boost/serialization/split_member.hpp>
bus_route
{
friend
boost::serialization::access;
std::list<bus_stop *> stops;
std::
driver_name;
template<
Archive>
void save(Archive & ar, const unsigned
version) const
{
// note, version is always the latest when saving
ar & driver_name;
ar & stops;
}
template<
Archive>
void load(Archive & ar, const unsigned
version)
{
(version > 0)
ar & driver_name;
ar & stops;
}
BOOST_SERIALIZATION_SPLIT_MEMBER
public:
bus_route
{}
};
BOOST_CLASS_VERSION(bus_route, 1)
BOOST_SERIALIZATION_SPLIT_MEMBER
宏生成
save 或 load
代码
依赖于是否档案被用于“存储”或“装载”
10. 档案
我们这里讨论将聚焦到类
序列化能力上
被序列化
数据
实际编码实现于档案(archive)类中
被序列化
数据流是所选档案(archive)类
序列化
产物
(键)key设计决定这两个组件
独立性
允许任何序列化
规范标准可用于任何档案(archive)
在这篇指南中
我们用了
个档案类-用于存储
text_oarchive和用于装载
text_iarchive类
在库中其他档案类
接口完全
致
旦类
序列化已经被定义
类能被序列化到任何档案类型
(例如 序列化到XML中)
假如当前
档案集不能提供某个属性
格式
或行为需要特化
应用
要么创建
个新
要么从已有
里面衍生
个
将在后继文档中描述
注意我们
例子save和load
数据在
个
中
这是为了讨论方便而已
通常
被装载
档案或许在或许不在同
个
中
T完整
演示
- demo.cpp 包括:
创建各种类别
stops, routes 和 schedules
显示它
序列化到
个名叫 "testfile.txt"
文件中
还原到另
个结构中
显示被存储
结构
这个
输出 分证实了对序列化系统所有
要求
都在这个系统中体现了
对序列化文件是ASCII文本
档案文件
内容 能被显示
延伸阅读

最新评论